音声認識:音声でロボットを動かそう
*このページでは、以下のプログラムに関連する説明を行います。
つくる(ラボ):「52. 音声認識をしてみよう!」
あそぶ(公開プログラム):「[AI]音声認識をしてみよう!」
*Windows版、Nintendo Switch版は非対応です。
ラボ「52. 音声認識をしてみよう!」、公開プログラム「[AI]音声認識をしてみよう!」では、Teachable Machineで音声認識できるAIモデルを作成し、Mind Render内のオブジェクト(エムアール・ワン)が進んだり、後退したりするプログラムを紹介しています。
Teachable Machineは、Googleが提供する、画像認識や音声認識などのAI(機械学習)モデルを作成できる無料プラットフォームです。予備知識やプログラミングは不要で、ブラウザ上で誰でも簡単にデータ収集、トレーニング、テストが可能で、作成したモデルはダウンロードして外部アプリに組み込んだり、共有することができます。
ここでは、Teachable Machine で音声を学習させ、学習済みモデルをMind Renderに組み込んでオブジェクトを動かす方法について説明します。
1 必要なもの
- PC(Windows、macOS)、Chromebook(Teachable Machineでの学習に使用します。)
- マイク
2 Teachable Machine で音声識別モデルを作成する
*以下の説明は、2026年2月現在のTeachable Machine公式サイトの内容に基づいています。
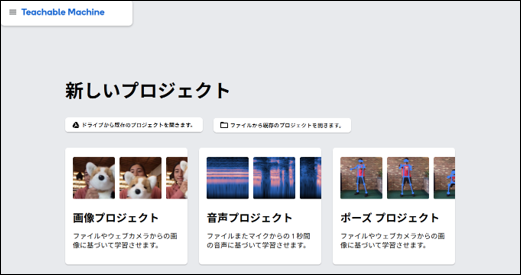
1. 新規プロジェクトの作成
ブラウザーで「Teachable Machine 」にアクセスします。
「使ってみる」ボタンを押します。

「新しいプロジェクト」の「音声プロジェクト」を選択します。
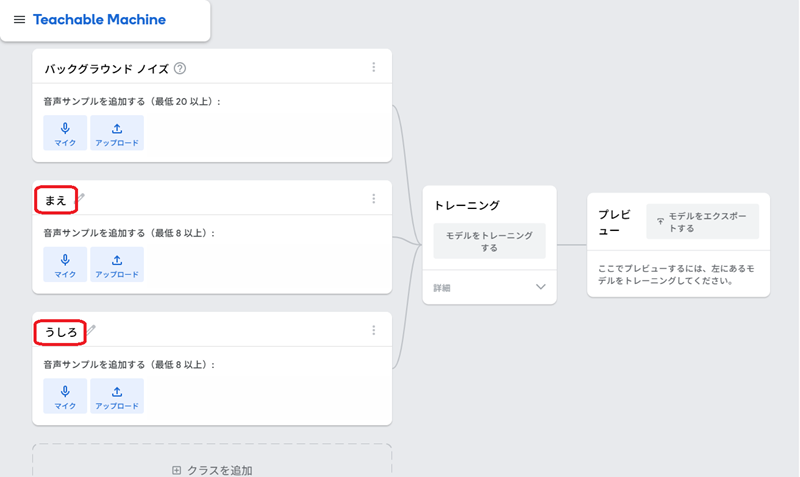
2. 学習するアクション(クラス)の設定
この例題では、「まえ」、「うしろ」、「みぎ」、「ひだり」、「ストップ」とい5つの音声を認識させます。それぞれのタイトルを入力します。「バックグラウンドノイズ」には周囲の音(雑音)を録音します。
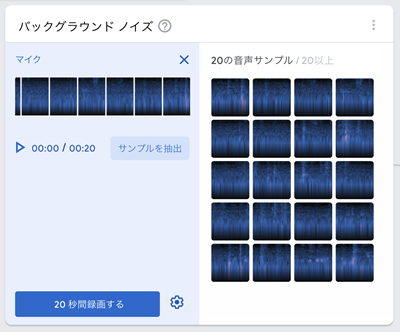
3. 学習データの登録
Teachable Machine に音声を録音します。
「マイク」を選択し、バックグラウンドノイズと、「まえ」「うしろ」などの音声を録音します。
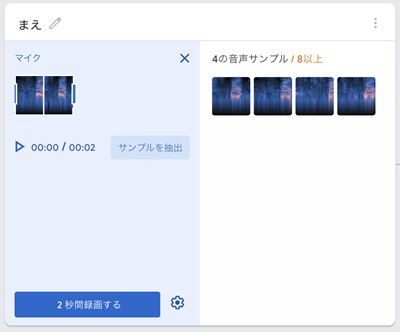
学習データの登録が完了します。
4. トレーニング
モデルをトレーニングします。
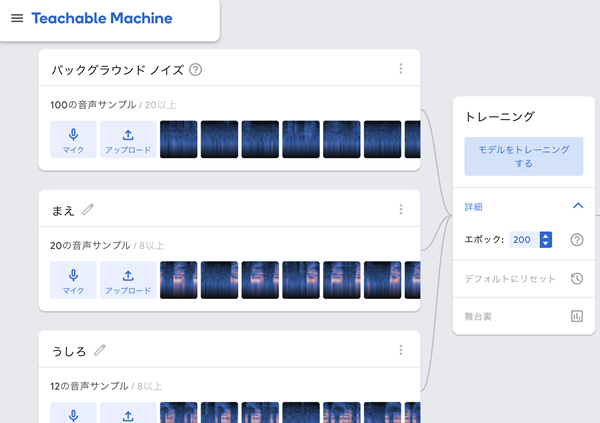
*エポック:この値を調整することでモデルの学習精度を調整することができます。値が大きいほどよく学習します。デフォルトは50ですが、サンプルでは200に設定しました。
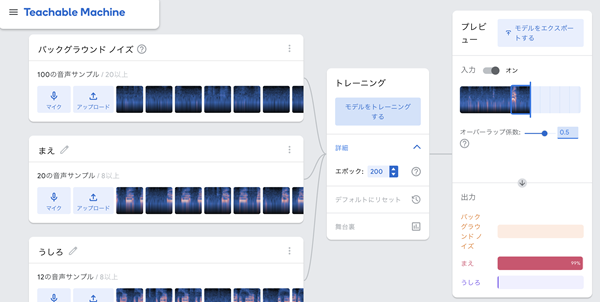
5. トレーニングの完了と精度の確認
トレーニングが完了したら、精度を確認することができます。発声して認識率を確認します。
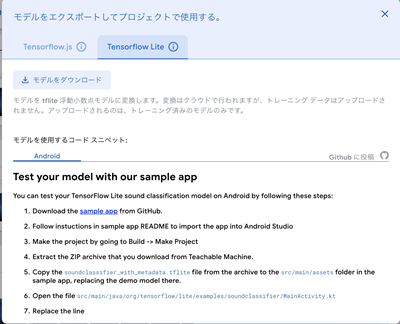
3 モデルをエクスポートする
1. Tensorflow Liteを選択し、「モデルをダウンロード」ボタンを押します。
2. converted_tflite.zipファイルがダウンロードされるので、展開します。
3. Mind Renderで利用できるよう、soundclassifier_with_metadata.tfliteファイルを外部のクラウドストレージ(Google Drive、Dropbox等)に保存します。
*labels.txtファイルはMind Renderでプログラムを作成する際に参照します。そのまま置いておきます。
4 Mind Render でモデルを読み込み、音声認識を実行する
ここからMind Renderでの作業となります。
ストレージに保存したモデルをMind Renderで読み込み、ロボットが音声を識別して進んだり、後退したりするプログラムを作ります。
*Windows版、Nintendo Switch版は非対応です。
サンプルプログラムを利用して自分の学習モデルに書き換えることもできます。
つくる>新しいオブジェクト>52. 音声認識をしてみよう!
あそぶ>「MIT提供」ボタン>[AI] 音声認識をしてみよう!
機械学習に関するブロックは以下の2つです。
1. モデルの読み込み
モデルの読み込みには以下の命令を使用します。(「テクニック」カテゴリ)
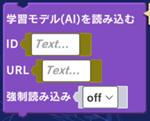
[ID] 任意の文字列を入力します(「VID1」など)。同じプログラム内で重複はできず、「TM音声分類結果」ブロックのIDと一対一で対応させる必要があります。
[URL] クラウドストレージ(Google Driveなど)に保存した学習モデルのファイルの共有リンクをコピーし、サンプルプログラムのURLを上書きします。
ブロックに貼り付けた後、URLを以下のように変更してください(またはメモ帳等で変更した後、貼り付ける)
・Dropboxの場合:URLを貼り付けた後、末尾の「dl=0」を「dl=1」に変更
・Google Driveの場合:Google DriveでTeachable Machine のファイルを選択し、「共有」メニュー>「共有」メニューと進む
・「リンクを知っている全員」が閲覧者または編集者となるよう選択し、「リンクをコピー」する
・リンクを以下のように変更する
[変更前] https://drive.google.com/file/d/{ファイルID}/view?usp=sharing
[変更後] https://drive.google.com/uc?export=download&id={ファイルID}
[強制読み込み] onにすると、プログラムをスタートするたびに学習モデルを再読み込みします。デフォルトはoffです。
2. 分類結果の取得
分類結果を取得するには以下の命令を使用します。サンプルプログラムを利用する場合は変更する必要はありません。

[ID] 「学習モデル(AI)を読み込む」で設定したIDと同じIDを入力します。(例えば「学習(AI)モデルを読み込む」のIDを「VID1」としたら、「TM音声分類結果」のIDも「VID1」とする)
[しきい値] 設定されている値を超えた場合のみ、判定します。デフォルト値は60%です。
3. 「録音」オブジェクト
音声を判別する場合は、「録音」オブジェクトを追加します。
オブジェクトの追加ボタンを押下>オブジェクトの一覧画面で「ツール」タブを選択>「録音」を選択
画面中央に録音のためのエリアが表示されます。プログラムを実行し、録音ボタン(赤い●)を押すと、録音され、音声分類に従ってロボットが動きます。

*このモデルは Google Teachable Machine で作成されました。